Comparison of SynDiffix, Mostly AI, and CTGAN
Compared to other commercial and open-source data synthesis tools, the strength of SynDiffix is its accuracy. Here we compare the accuracy of open-source SynDiffix with the commercial tool Mostly AI and the open-source tool CTGAN from SDV.
For this comparison, we use the Czech banking dataset. See here for a description of how we generated the synthetic datasets. Note in particular that we used the tools as they were designed to be used: multiple synthetic datasets for SynDiffix, and single datasets for Mostly AI and CTGAN. See here for a discussion of how this comparison is and isn’t fair.
The code for some of the following examples can be found here.
Average account balance by type of credit card
892 of the 4500 bank accounts have credit cards. There are three classes of card, ‘junior’, ‘classic’, and ‘gold’. Here we ask the question, “Does the average account balance differ based on the credit card class?”
The following graphs are percentile boxplots (100th, 75th, 50th, 25th, and 0th percentiles, plus outliers) of the average account balance for each account with a credit card. The two plots show the same data, but grouped by synthesis method on the left, and by card type on the right.
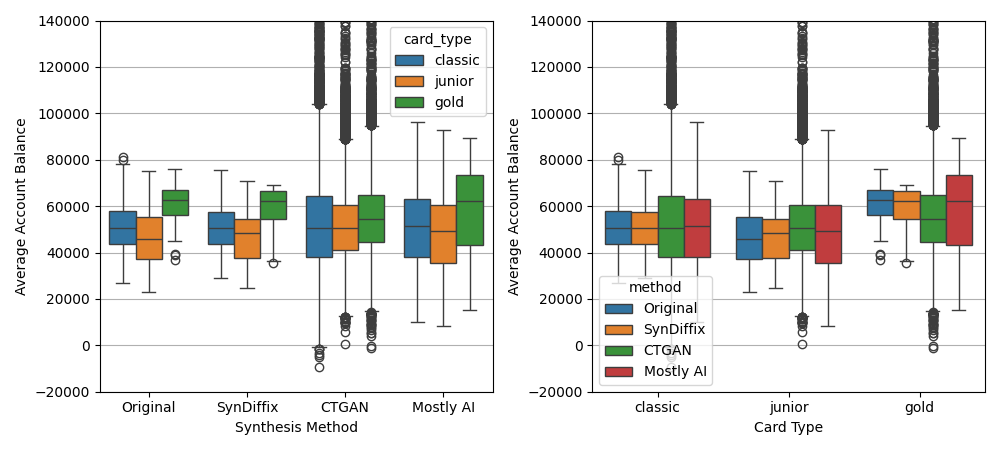
The SynDiffix synthetic data was produced by first computing the average balance per account from the original data to produce a two-column table consisting of the avg_balance and the card_type, with one row per account (i.e. not time-series data). This two-column table was then synthesized.
From the original data, we see that indeed gold credit card holders have higher average account balances than classic card holders, which in turn are a little higher than junior card holders. The data for SynDiffix is very close to the original data, and accurately shows the same trend. The high and low values are pulled in a little bit, which is due to SynDiffix’ tendency to hide outlier values.
Mostly AI also shows the same trend, and the median account balances track the original data very closely. In contrast to SynDiffix, the high and low account balances tend to be spread out.
While CTGAN shows the median account balance to be slightly higher for gold card holders, overall it does not capture the trend. Its high and low values are extreme, in some cases showing negative balances where none should exist.
Distribution of deposit and withdrawal amounts
There are five types of transaction operations. One of them represents deposits (VKLAD), while the other four represent different types of withdrawals (at least as near as we can tell from the Czech translations).
The following graph shows the distribution of deposit and withdrawal amounts for all transactions. Each line is independently sorted from largest to smallest amount. The group of lines on the left are for deposits, which are less numerous.
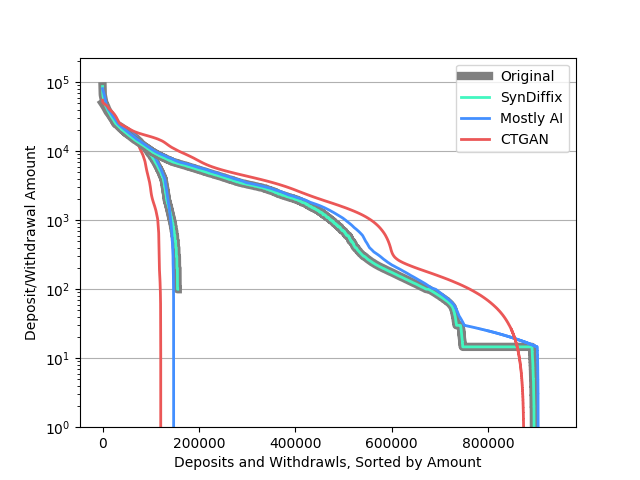
The SynDiffix data was created be first creating a two-column table from the original data consisting of transaction amount and transaction type. This was then synthesized to produce the synthetic dataset.
The important thing to note is that the SynDiffix lines almost perfectly track the original lines. Note that it was necessary to make the Original line thicker so that it is not completely occluded by the SynDiffix line.
For withdrawals, Mostly AI tracks the original data very well until the lower right, where Mostly AI fails to accurately track a series of nearly 200k withdrawals all at around 150 units. Mostly AI also tracks original deposits well, except that there are a small number of small deposits that don’t appear in the original data. CTGAN is substantially less accurate overall.
Total transaction volume per month
The following plot shows the total transaction volume (sum of all transaction amounts) for each month.
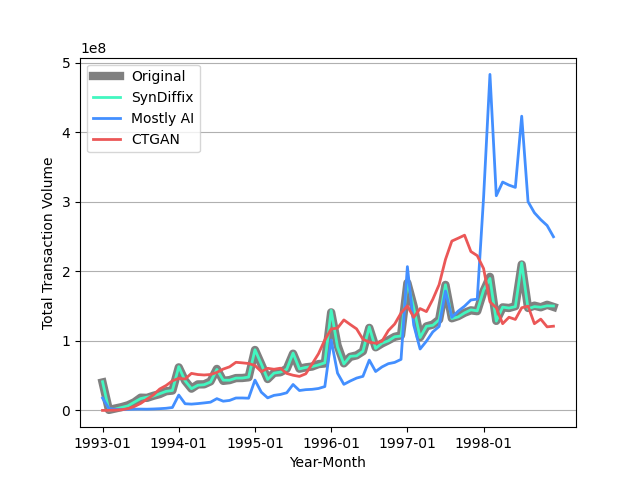
The SynDiffix data was produced by rounding the transaction date to the month, and then producing a two-column table with month and amount. This table was then synthesized.
Once again, the SynDiffix line tracks the original data almost perfectly.
While both the Mostly AI and CTGAN transactions have the right increasing trend, both are quite inaccurate.
Distribution of maximum balance for all accounts
The following plot gives the distribution of the maximum balance for each account. Each line is sorted independently from highest to lowest maximum balance.
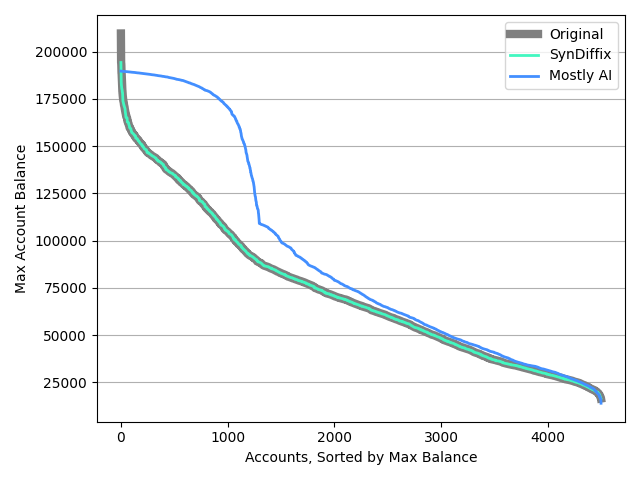
The SynDiffix data was produced by first computing the maximum balance for each account from the original data, creating a one-column table consisting of the maximum balance, with one row per account. This was then synthesized.
The CTGAN line is not shown because it is too far away from the other lines.
SynDiffix tracks the original data almost perfectly, with the exception that a small number of the highest maximum balances are not tracked. SynDiffix suppresses these values because they are outliers that pertain to too few accounts. The Mostly AI line is far less accurate.
How the synthetic data was created
The Czech banking dataset has seven relational tables. Three of them (loans, orders, and transactions) are time-series tables. The others contain information about clients (banking customers), accounts, and credit cards. To build the synthetic datasets, we joined the client, account, and credit card information with the time-series data to create three extended tables. We then built three synthetic datasets each for Mostly AI and CTGAN from the three extended tables.
Our comparison uses only the extended transactions table. It has the following 21 columns:
| Column | Source table |
|---|---|
| trans_id | trans |
| account_id | trans |
| date | trans |
| type | trans |
| operation | trans |
| amount | trans |
| balance | trans |
| k_symbol | trans |
| bank | trans |
| account | trans |
| district_id | account |
| frequency | account |
| account_date | account |
| card_type | card |
| card_issued | card |
| owner_birth | client |
| owner_district_id | client |
| owner_sex | client |
| disponent_birth | client |
| disponent_district_id | client |
| disponent_sex | client |
To make the Mostly AI synthetic dataset, we used the free service available at mostly.ai. We used the subject-linked option, which captures the time series aspect of the data. We built a synthetic dataset with the same number of accounts (4500) and nearly the same number of rows (1059409) as the original table.
To make the CTGAN synthetic dataset, we used the SDV Python tool. SDV has options for synthesizing both time-series and non-time-series, but unfortunately we were unable to make a time-series dataset because our system did not have enough memory (the system had 1.5TB of memory, but this was not enough). Therefore, we used the non-time-series option to build a synthetic dataset with the same number of rows as the original table (1056320), but with around 10k accounts.
Both the Mostly AI and CTGAN datasets were built using system defaults.
How the comparison is and isn’t fair
The usage style of SynDiffix is different from that of other synthetic data tools. SynDiffix is designed to remain anonymous no matter how many different synthetic datasets are built from the original data. This allows us to build synthetic datasets containing only the columns of interest for the given analysis question. This maximizes accuracy. We built a separate SynDiffix synthetic dataset for each of the comparison examples.
By contrast, we built only a single transactions synthetic dataset each for Mostly AI and CTGAN. All of the comparison examples used these datasets. In principle, we could have also built separate datasets for each comparison example for Mostly AI and CTGAN. Doing so would have resulted in better accuracy (though probably still not as good as SynDiffix, as this paper shows). In this sense, the comparison is not apples-to-apples.
Nevertheless, we choose to make the comparison this way for the following reasons:
Synthetic data products are marketed as one-size-fits-all
Synthetic data products are marketed as one-size-fits-all: the promise is that a single dataset accurately captures the statistical characteristics of the original data. It seems fair to take this marketing at its word, and use it as it is designed to be used.
The privacy of synthetic data products erodes with multiple syntheses
Unlike SynDiffix, the anonymity of other synthetic data products weakens with each data synthesis, at least in theory. As such, a comparison of multiple SynDiffix synthetic datasets against a single Mostly AI or CTGAN synthetic dataset is fair from a privacy perspective. Whether generating a large number of synthetic datasets with other products results in real risks in practice is unknown, though it does seem unlikely that generating a relatively small number of datasets leads to practical risks.