SynDiffix
SynDiffix is an open-source Python package for generating statistically-accurate and strongly anonymous synthetic data from structured data. Compared to existing open-source and proprietary commercial approaches, SynDiffix is
- many times more accurate,
- has comparable or better ML efficacy,
- runs as fast or faster,
- has stronger anonymization.
A complete description of SynDiffix, including its operation, performance, and anonymity, can be found on arXiv. See github.com/diffix/syndiffix.
Programming with SynDiffix can be as easy as:
from syndiffix import Synthesizer
df_synthetic = Synthesizer(df_original).sample()
Use Cases
The high accuracy of SynDiffix makes it a good choice for descriptive analytics — histograms, heatmaps, column correlations, basic statistics like counting, averages, standard deviations, and so on. SynDiffix works well for accurately capturing the statistics of both time-series data (events like transactions and mobility) and non-time-series data (demographics, surveys).
SynDiffix is ideal for releasing accurate data statistics while strongly protecting anonymity. It is far easier to use than K-anonymity and Differential Privacy, and far more accurate than other synthetic data methods for descriptive analytics.
SynDiffix can also be used for Machine Learning use cases (building models, extending datasets, etc.). It’s ML models are on a par with other synthetic data methods, but it is somewhat less easy to use for ML applications.
Usage
Obtaining its accuracy improvement requires a different usage style compared to other products. The intended usage style of other products is “one size fits all”: a single monolithic synthetic dataset serves all use cases. It’s like expecting a vehicle to be good at city maneuverability, highway cruising, and hauling lumber.
By contrast, with SynDiffix, a different tailored synthetic dataset can be produced for each use case: like having a Smart car for the city, a Mercedes S-class for the highway, and a Ford F-150 for hauling stuff.
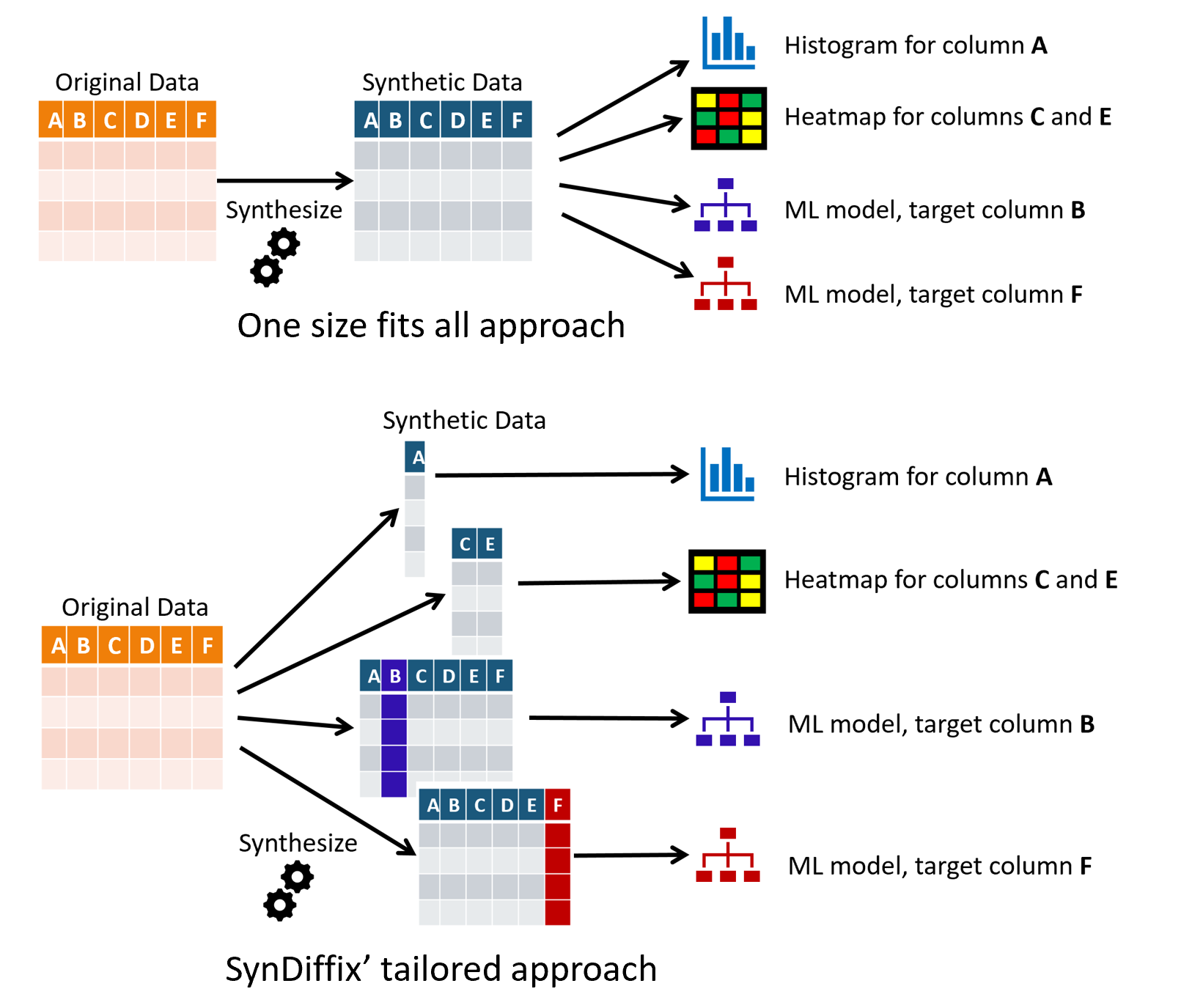
For instance, suppose the analyst is interested in a heatmap with columns C and E. With other synthetic data products, one would synthesize the complete table, and then make the heatmap with only columns C and E. With SynDiffix, one would create a synthetic table consisting of only those two columns and obtain much better results.
SynDiffix has anonymization mechanisms that allow for literally thousands of column combinations without compromising anonymity. This is not the case with other products, where anonymity is weakened with each new data synthesis.
Accuracy
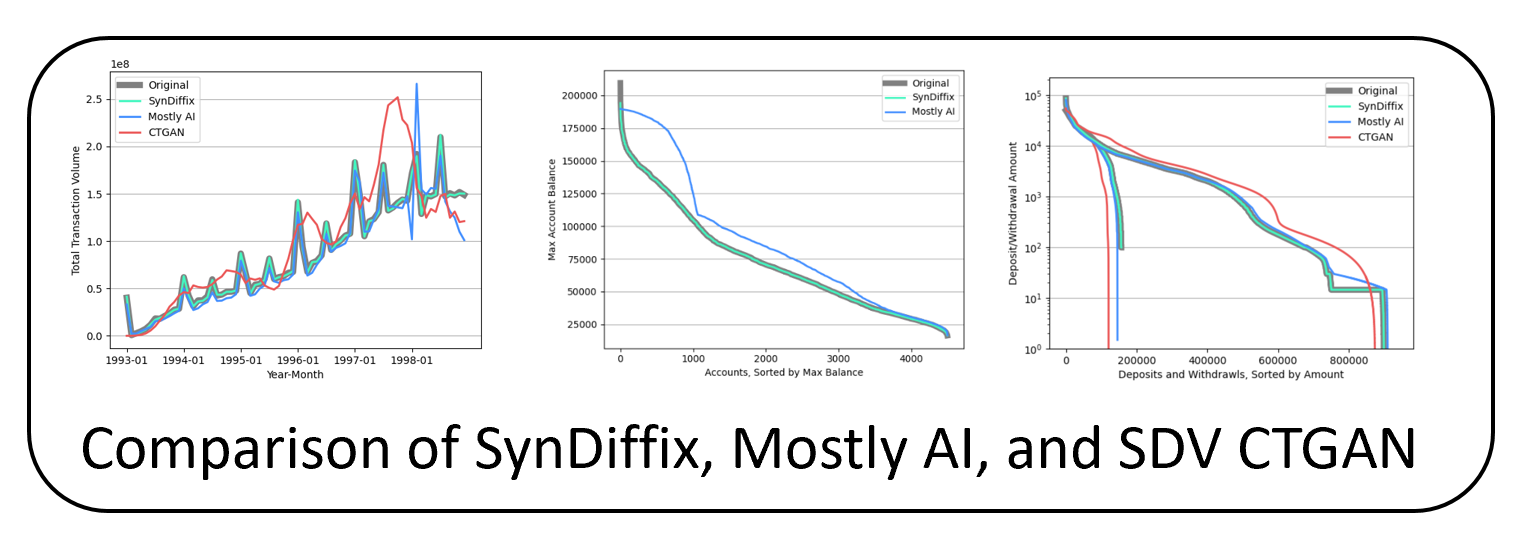
Here are three scatter plots showing the synthetic and real points for a 2-column dataset for SynDiffix, the commercial product MostlyAI, and the open-source implementation of CTGAN by SDV.
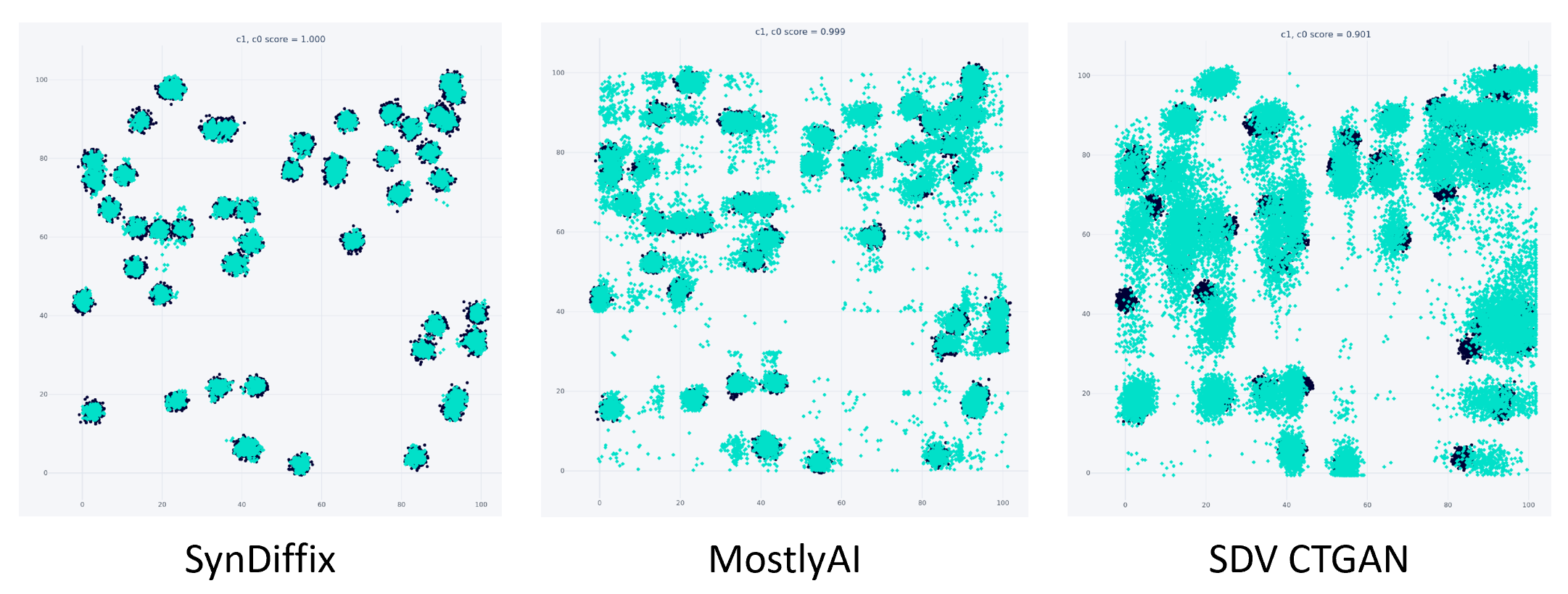
The black dots are the original data and the blue dots are the synthetic overlaid on the original data. SynDiffix is far more accurate. More examples can be found here or in the arXiv paper.
Anonymity
We measured the anonymity of SynDiffix and a number of other products using the Anonymeter tool developed by Statice. The following figure shows the results of measuring the effectiveness of 100s of attacks over multiple different tables (again, see the arXiv paper for details). Any score below 0.5 can be regarded as having strong anonymity, and scores below 0.2 are very strong. The “noAnon” plot measures attacks against the original data, and is there for calibration.
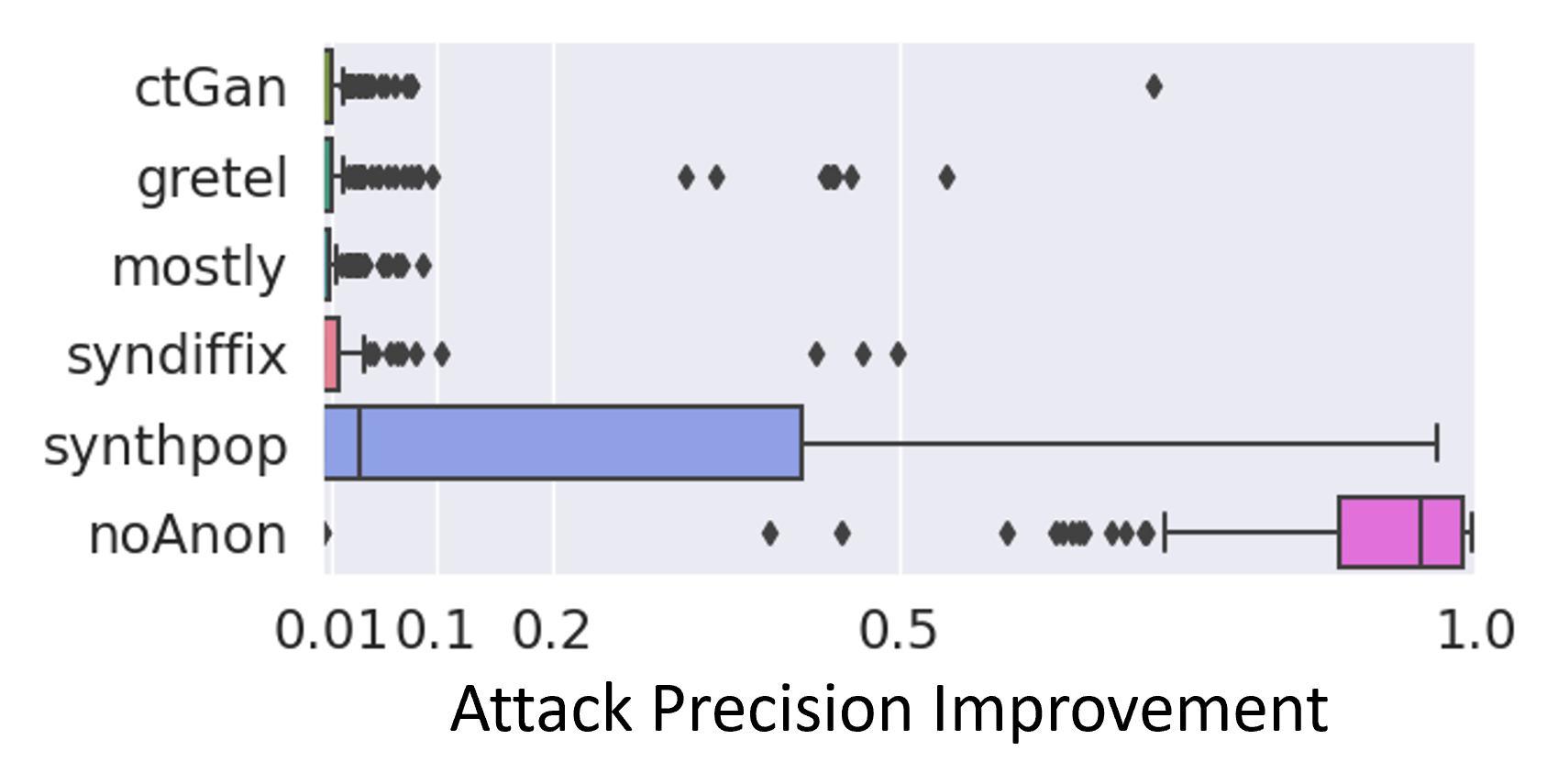
As these results show, SynDiffix and most of the other products have very strong anonymization with respect to the attack used by Anonymeter.